|
Hi, I'm Zheyu! I am a PhD student at Technical University of Munich, advised by Gjergji Kasneci. Prior to that, I studied at LMU Munich, where I obtained my bachelor's degree in computer science and mathematics, and master's degree in computational linguistics. My research currently focuses on generative modeling, LLM post-training, synthetic data generation, and diffusion LLMs. Email / GitHub / Google Scholar / LinkedIn / CV |

|
NewsAug '25 🦀 Three papers are accepted to EMNLP 2025! See you in Suzhou! May '25 🎻 One paper is accepted to ACL 2025! See you in Vienna! Dec '24 🥳 I start my PhD journey!!! Jan '24 🦞 One paper is accepted to EACL 2024 and I will be in Malta as a student volunteer! Oct '23 🍼 One paper is accepted to BabyLM Challenge @CoNLL 2023! |
Selected Publications |
|
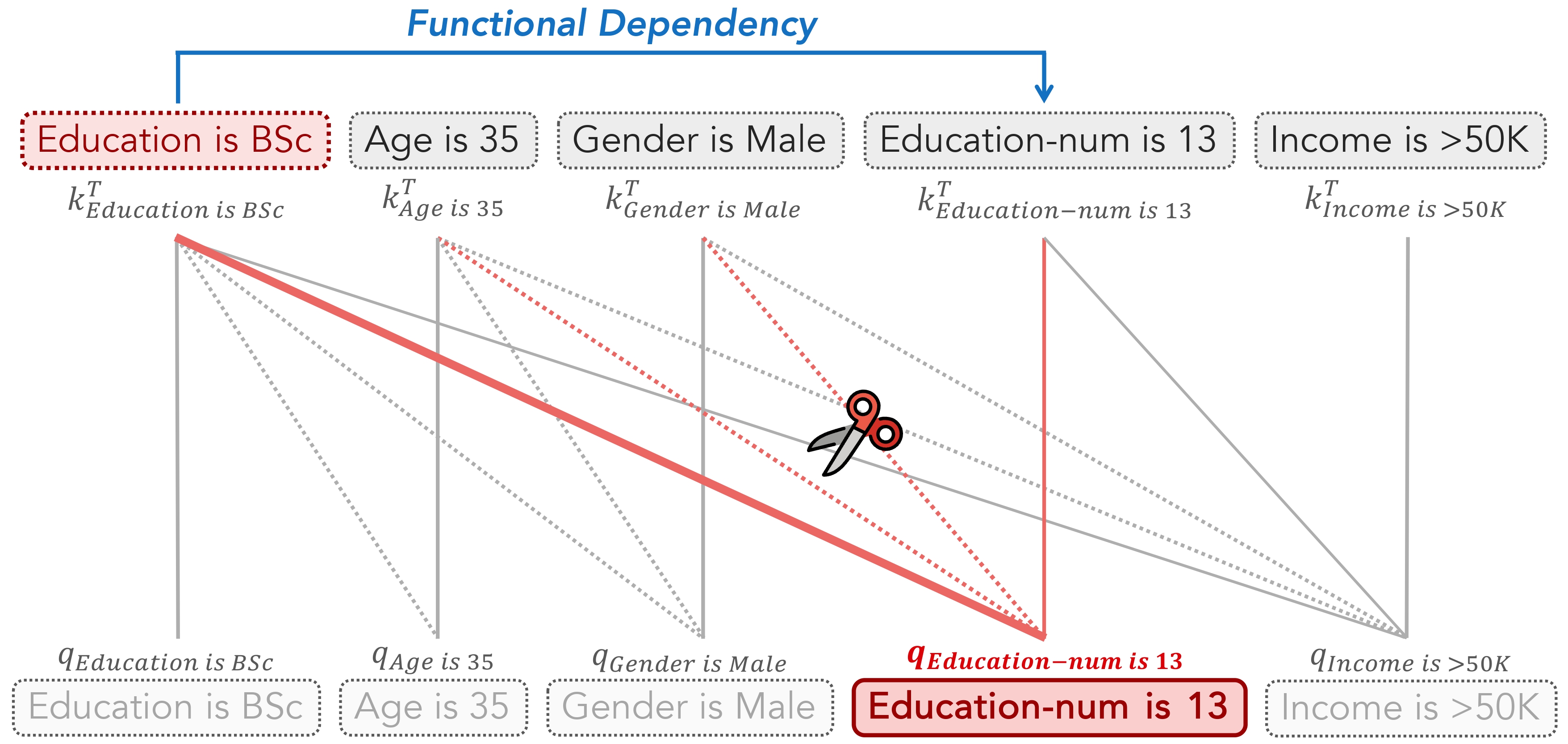
Not All Features Deserve Attention: Graph-Guided Dependency Learning for Tabular Data Generation with Language ModelsZheyu Zhang, Shuo Yang, Bardh Prenkaj, Gjergji Kasneci EMNLP 2025 Findings paper / code / We propose a minimally intrusive and structure-aware approach for tabular data synthesis by guiding LLMs attention with sparse feature dependencies. |
|
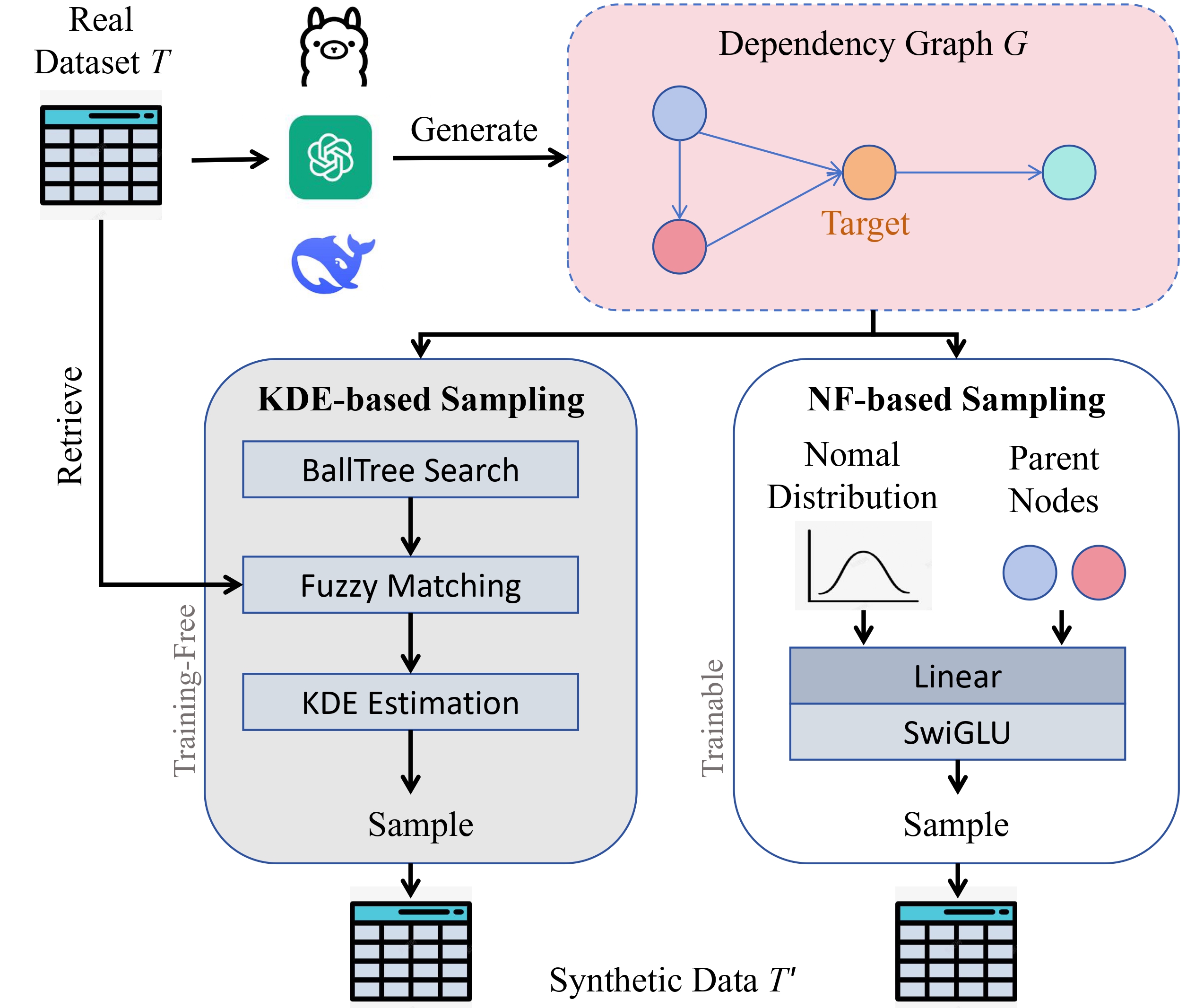
Doubling Your Data in Minutes: Ultra-fast Tabular Data Generation via LLM-Induced Dependency GraphsShuo Yang, Zheyu Zhang, Bardh Prenkaj, Gjergji Kasneci EMNLP 2025 paper / code / We propose a lightweight framework for tabular data augmentation that models sparse dependencies and accelerates generation by over 9,500× than LLM-based approaches while reducing constraint violations. |
|
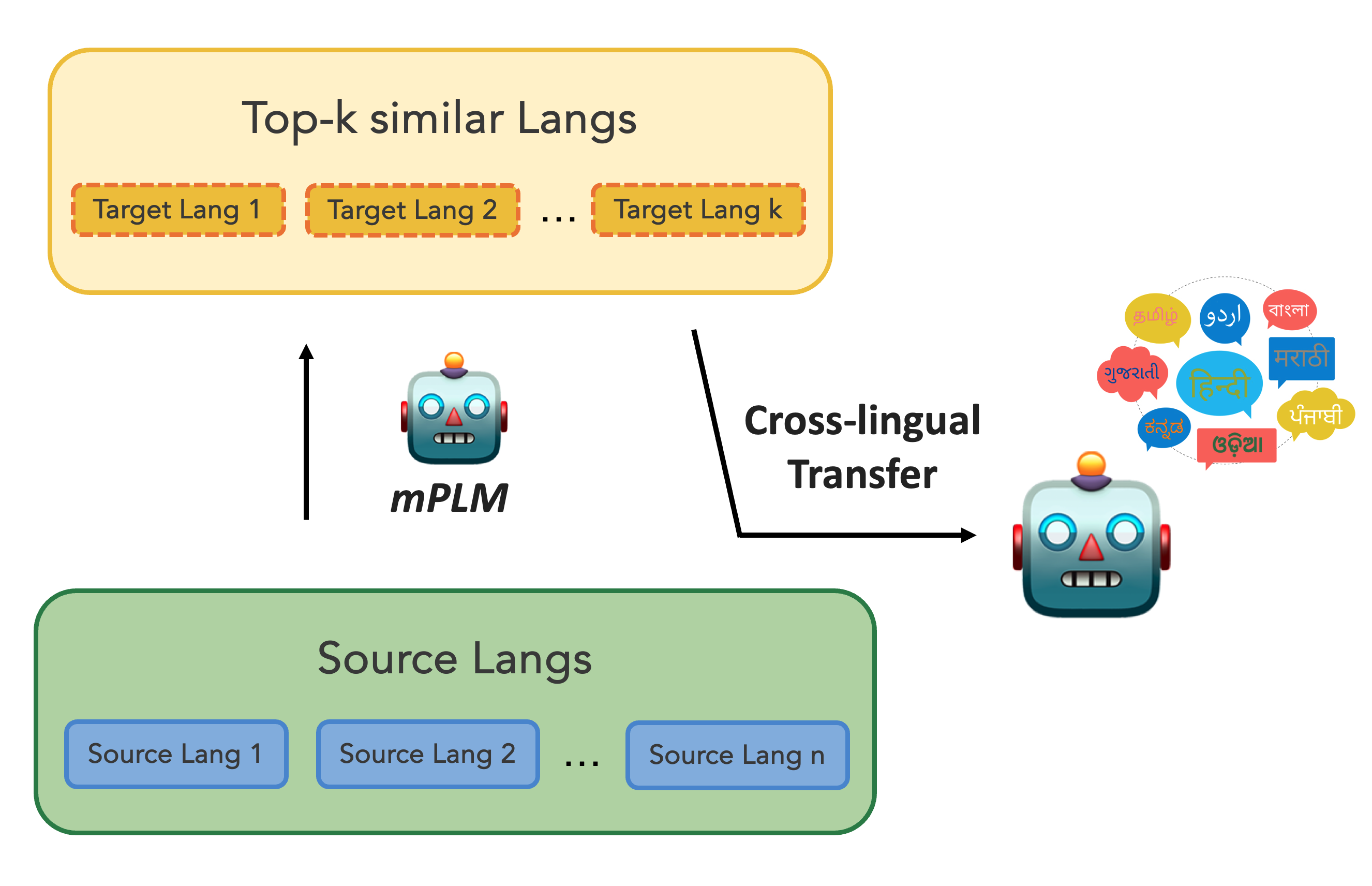
mPLM-Sim: Better Cross-Lingual Similarity and Transfer in Multilingual Pretrained Language ModelsPeiqin Lin, Chengzhi Hu, Zheyu Zhang, André FT Martins, Hinrich Schütze EACL 2024 Findings paper / code / We evaluate the effectiveness of various mPLMs in measuring language similarity and improved zero-shot cross-lingual transfer performance based on the results. |
|
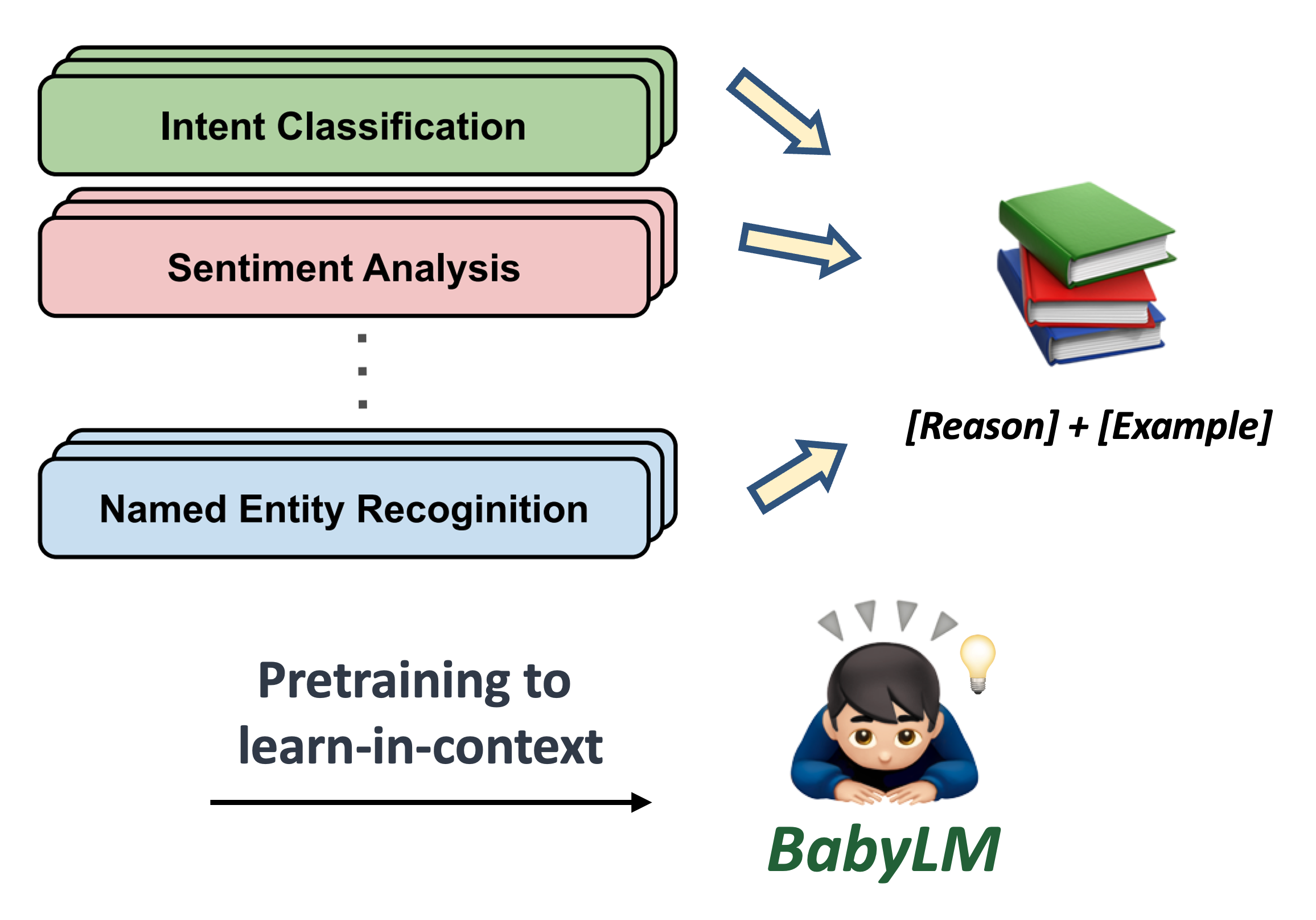
Baby’s CoThought: Leveraging Large Language Models for Enhanced Reasoning in Compact ModelsZheyu Zhang, Han Yang, Bolei Ma, David Rügamer, Ercong Nie EMNLP 2023 Workshop CoNLL-CMCL Shared Task BabyLM Challenge paper / code / We propose using LLMs to reconstruct existing data into NLU examples for training compact LMs, demonstrating the effectiveness of synthetic data in small LM training. |
Experience
|
Academic Service
|
|
|